Хотим поделиться с вами полезными SQL-запросами к PostgreSQL. Считаем, что это крайне важно для возможной оптимизации схемы хранения геоданных и для общего понимания вашей базы геоданных.
Получение размеров БД
Это важно для настройки и отслеживания процесса бекапа БД, для возможности распределения БД на разные диски сервера, для актуальности вынесения каких тяжелых, но при этом выделенных схем из общей БД в отдельную.
SELECT datname, pg_database_size(datname)/1024.0/1024/1024 as size_in_gb, pg_size_pretty(pg_database_size(datname))
FROM pg_database
WHERE datistemplate = false
order by pg_database_size(datname) desc;

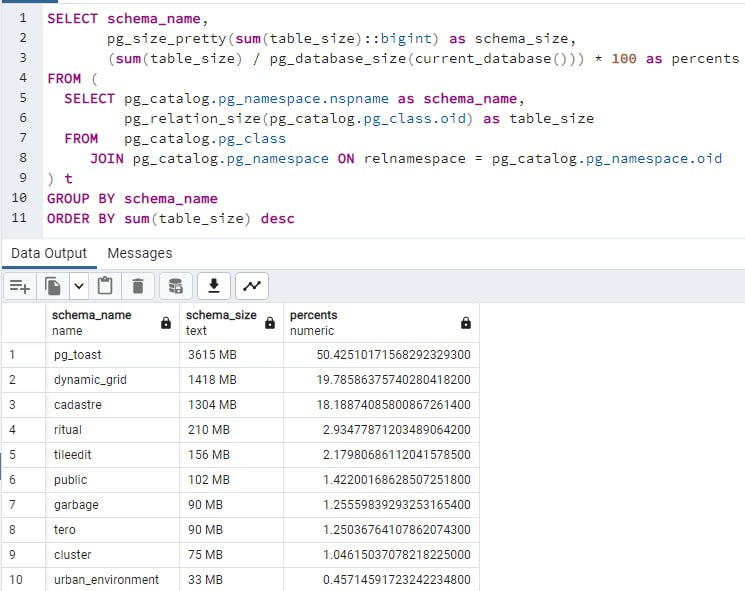
Получение размеров схем в текущей БД
SELECT schema_name, pg_size_pretty(sum(table_size)::bigint) as schema_size, (sum(table_size) / pg_database_size(current_database())) * 100 as percents
FROM (
SELECT pg_catalog.pg_namespace.nspname as schema_name, pg_relation_size(pg_catalog.pg_class.oid) as table_size
FROM pg_catalog.pg_class
JOIN pg_catalog.pg_namespace ON relnamespace = pg_catalog.pg_namespace.oid
) t
GROUP BY schema_name
ORDER BY sum(table_size) desc

Получение информации о размерах наиболее тяжёлых таблиц
Как правило с blob-полями и со сложными полигональными геометриями.
Как правило, в топ попадают:
- ATTACH-таблицы с файловыми вложениями (если вы их храните в БД, а не файлами на диске, как мы писали ранее в этом чате)
- классы пространственных объектов со сложными геометриями (как правильно, полигональными), где кол-во точек может быть запредельным (обычно, этим грешат лесные массивы и водные объекты с ненужной детальностью)
- какие-то лог-таблицы, которые могут неконтролируемо пухнуть
SELECT oid::regclass, reltoastrelid::regclass, pg_size_pretty(pg_relation_size(reltoastrelid)) AS toast_size
FROM pg_class
WHERE relkind = 'r' AND reltoastrelid <> 0
ORDER BY pg_relation_size(reltoastrelid) DESC;
Список sql-запросов, выполняемых в данный момент
Это позволит:
- во-первых, понимать, какие именно sql-запросы формируются к СУБД в процессе использования ваших веб-карт в CoGIS
- во-вторых, выявлять долго выполняемые запросы, добавляя недостающих индексов на поля или неоптимальные запросы сами по себе
Также, если убрать sql-фильтр (строку с WHERE), то можно посмотреть недавно выполненные sql-запросы.
SELECT datname, pid, state, query, age(clock_timestamp(), query_start) AS age
FROM pg_stat_activity
WHERE state <> 'idle' AND query NOT LIKE '% FROM pg_stat_activity %'
ORDER BY age;
